
Hash table (creating, collisions)
Hash Table is a data structure which stores data in an associative manner. In a hash table, data is stored in an array format, where each data value has its own unique index value. Access of data becomes very fast if we know the index of the desired data.
Thus, it becomes a data structure in which insertion and search operations are very fast irrespective of the size of the data. Hash Table uses an array as a storage medium and uses hash technique to generate an index where an element is to be inserted or is to be located from.
Hashing is a technique that is used to uniquely identify a specific object from a group of similar objects. Some examples of how hashing is used in our lives include:
In universities, each student is assigned a unique roll number that can be used to retrieve information about them.
In libraries, each book is assigned a unique number that can be used to determine information about the book, such as its exact position in the library or the users it has been issued to etc.
In both these examples the students and books were hashed to a unique number.
Assume that you have an object and you want to assign a key to it to make searching easy. To store the key/value pair, you can use a simple array like a data structure where keys (integers) can be used directly as an index to store values. However, in cases where the keys are large and cannot be used directly as an index, you should use hashing.
In hashing, large keys are converted into small keys by using hash functions. The values are then stored in a data structure called hash table. The idea of hashing is to distribute entries (key/value pairs) uniformly across an array. Each element is assigned a key (converted key). By using that key you can access the element in O(1) time. Using the key, the algorithm (hash function) computes an index that suggests where an entry can be found or inserted.
Hashing is implemented in two steps:
An element is converted into an integer by using a hash function. This element can be used as an index to store the original element, which falls into the hash table.
The element is stored in the hash table where it can be quickly retrieved using hashed key.
hash = hashfunc(key) index = hash % array_size
In this method, the hash is independent of the array size and it is then reduced to an index (a number between 0 and array_size − 1) by using the modulo operator (%).
Hash function
A hash function is any function that can be used to map a data set of an arbitrary size to a data set of a fixed size, which falls into the hash table. The values returned by a hash function are called hash values, hash codes, hash sums, or simply hashes.
To achieve a good hashing mechanism, It is important to have a good hash function with the following basic requirements:
Easy to compute: It should be easy to compute and must not become an algorithm in itself.
Uniform distribution: It should provide a uniform distribution across the hash table and should not result in clustering.
Less collisions: Collisions occur when pairs of elements are mapped to the same hash value. These should be avoided.
Irrespective of how good a hash function is, collisions are bound to occur. Therefore, to maintain the performance of a hash table, it is important to manage collisions through various collision resolution techniques.
Hash table A hash table is a data structure that is used to store keys/value pairs. It uses a hash function to compute an index into an array in which an element will be inserted or searched. By using a good hash function, hashing can work well. Under reasonable assumptions, the average time required to search for an element in a hash table is O(1).
Collisions
What is Collision?
Since a hash function gets us a small number for a key which is a big integer or string, there is a possibility that two keys result in the same value. The situation where a newly inserted key maps to an already occupied slot in the hash table is called collision and must be handled using some collision handling technique.
What are the chances of collisions with large table?
Collisions are very likely even if we have big table to store keys. An important observation is Birthday Paradox. With only 23 persons, the probability that two people have the same birthday is 50%.
How to handle Collisions?
There are mainly two methods to handle collision:
Separate Chaining
Open Addressing
Separate Chaining
The idea is to make each cell of hash table point to a linked list of records that have same hash function value.
Let us consider a simple hash function as “key mod 7” and sequence of keys as 50, 700, 76, 85, 92, 73, 101.
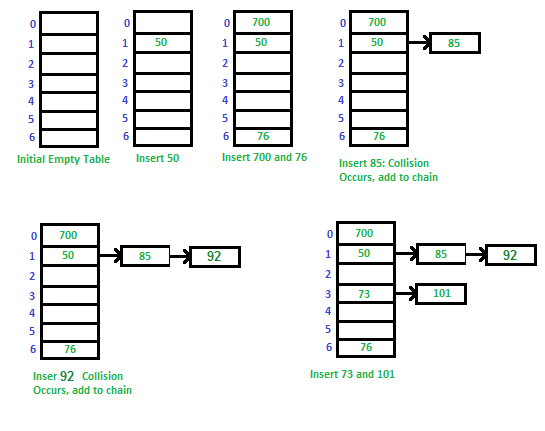
Advantages
Simple to implement.
Hash table never fills up, we can always add more elements to the chain.
Less sensitive to the hash function or load factors.
It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
Disadvantages
Cache performance of chaining is not good as keys are stored using a linked list. Open addressing provides better cache performance as everything is stored in the same table.
Wastage of Space (Some Parts of hash table are never used)
If the chain becomes long, then search time can become O(n) in the worst case.
Uses extra space for links.
As you might be knowing that hash table data structure works on key value pairing. The idea behind using of Hash table is it would work with O(1) time complexity for insertion, deletion and search operations in Hash Table for any given value. O(1) time complexity can be achieved if we have a key for each value. Calculation of key for a given value is done by hash functions. eg.- If we want to do some operations on characters used in a string we can use ASCII value of characters as key. This way each character (value) would be mapped to different ascii (key). Suppose if you also want to keep track of number of occurrences of characters or you want to store repeated characters also in hash table than collision will occur. Because repeated characters will collide with already stored characters in has table for the keys. In this example it may not look a big deal as characters are identical but in some other cases it would affect the desired result of O(1). In worst case operations can cost O(n). So collisions occur when more than one value link to single key in hash table. We can add values in linked list for that key in such cases.
To avoid the collision hash function should be properly picked. It can also depend on the size of hash table. If you have wide range of inputs its quite possible that for a particular set of input you will always get worst case O(n) time complexity. To overcome that we can have a set of hash functions and we can randomly pic a hash function on execution. This would avoid the situations where a given input always leads to worst case performance. There are some other techniques also like Open Addressing. You can refer Cormen Book to know more about it.
Last updated